Concepts: Key
Measures of Test
Topics
Introduction 
The key measures of a test include coverage and quality.
Test coverage is the measurement of testing completeness, and it's based on the coverage of testing expressed by the coverage of test requirements and test cases or by the coverage of executed code.
Quality is a measure of the reliability, stability, and performance of the target-of-test (system or application-under-test). Quality is based on evaluating test results and analyzing change requests (defects) identified during testing.
Coverage Measures
Coverage metrics provide answers to the question: "How complete is the testing?" The most commonly-used measures of coverage are based on the coverage of software requirements and source code. Basically, test coverage is any measure of completeness with respect to either a requirement (requirement-based), or the code's design and implementation criteria (code-based), such as verifying use cases (requirement-based) or executing all lines of code (code-based).
Any systematic testing activity is based on at least one test coverage strategy. The coverage strategy guides the design of test cases by stating the general purpose of the testing. The statement of coverage strategy can be as simple as verifying all performance.
A requirements-based coverage strategy might be sufficient for yielding a quantifiable measure of testing completeness if the requirements are completely cataloged. For example, if all performance test requirements have been identified, then the test results can be referenced to get measures; for example, 75% of the performance test requirements have been verified.
If code-based coverage is applied, test strategies are formulated in terms of how much of the source code has been executed by tests. This type of test coverage strategy is very important for safety-critical systems.
Both measures can be derived manually (using the equations given in the next two headings) or may be calculated using test automation tools.
Requirements-based Test Coverage
Requirements-based test coverage, measured several times during the test lifecycle, identifies the test coverage at a milestone in the testing lifecycle, such as the planned, implemented, executed, and successful test coverage.
- Test coverage is calculated using the following equation:
Test Coverage = T(p,i,x,s) / RfT
where:
T is the number of Tests (planned, implemented, executed, or successful), expressed as test procedures or test cases.RfT is the total number of Requirements for Test.
- In the Plan Test activity, the test coverage is calculated to determine the planned test coverage in the following manner:
Test Coverage (planned) = Tp / RfT
where:
Tp is the number of planned Tests, expressed as test procedures or test cases.RfT is the total number of Requirements for Test.
- In the Implement Test activity, as test procedures are being implemented (as test scripts) test coverage is calculated using the following equation:
Test Coverage (implemented) = Ti / RfT
where:
Ti is the number of Tests implemented, expressed by the number of test procedures or test cases for which there are corresponding test scripts.RfT is the total number of Requirements for Test.
- In the Execute Test activity, there are two test coverage measures used-one
identifies the test coverage achieved by executing the tests and the second
identifies the successful test coverage (those tests that executed without
failures, such as defects or unexpected results).
These coverage measures are calculated using the following equations:
Test Coverage (executed) = Tx / RfT
where:
Tx is the number of Tests executed, expressed as test procedures or test cases.RfT is the total number of Requirements for Test.
Successful Test Coverage (executed) = Ts / RfT
where:
Ts is the number of Tests executed, expressed as test procedures or test cases that completed successfully, without defects.RfT is the total number of Requirements for Test.
Turning the above ratios into percentages allows for the following statement of requirements-based test coverage:
x% of test cases (T(p,i,x,s) in the above equations) have been covered with a success rate of y%
This meaningful statement of test coverage can be matched against a defined success criteria. If the criteria have not been met, then the statement provides a basis for predicting how much testing effort remains.
Code-based Test Coverage
Code-based test coverage measures how much code has been executed during the test, compared to how much code is left to execute. Code coverage can be based on control flows (statement, branch, or paths) or data flows.
- In control-flow coverage, the aim is to test lines of code, branch conditions, paths through the code, or other elements of the software's flow of control.
- In data-flow coverage, the aim is to test that data states remain valid through the operation of the software; for example, that a data element is defined before it's used.
Code-based test coverage is calculated by the following equation:
Test Coverage = Ie / TIic
where:
Ie is the number of items executed, expressed as code statements, code branches, code paths, data state decision points, or data element names.
TIic is the total number of items in the code.
Turning this ratio into a percentage allows the following statement of code-based test coverage:
x% of test cases (I in the above equation) have been covered with a success rate of y%
This meaningful statement of test coverage can be matched against a defined success criteria. If the criteria have not been met, then the statement provides a basis for predicting how much testing effort remains.
Measuring
Perceived Quality
Although evaluating test coverage provides a measure of the extent of completeness of the testing effort, evaluating defects discovered during testing provides the best indication of the software quality as it has been experienced. This perception of quality can be used to reason about the general quality of the software system as a whole. Perceived Software Quality is a measure of how well the software meets the requirements levied on it, therefore, in this context, defects are considered as a type of change request in which the target-of-test failed to meet the software requirements.
Defect evaluation could be based on methods that range from simple defect counts to rigorous statistical modeling.
Rigorous evaluation uses assumptions about the arrival or discovery rates of defects during the testing process. A common model assumes that the rate follows a Poisson distribution. The actual data about defect rates are then fit to the model. The resulting evaluation estimates the current software reliability and predicts how the reliability will grow if testing and defect removal continue. This evaluation is described as software-reliability growth modeling and it's an area of active study. Due to the lack of tool support for this type of evaluation, you want to carefully balance the cost of using this approach with the benefits gained.
Defects analysis involves analyzing the distribution of defects over the values of one or more of the attributes associated with a defect. Defect analysis provides an indication of the reliability of the software.
In defect analysis, four main defect attributes are commonly analyzed:
- Status - the current state of the defect (open, being fixed, closed, and so forth).
- Priority - the relative importance of this defect being addressed and resolved.
- Severity - the relative impact of this defect to the end-user, an organization, third parties, and so on.
- Source - where and what is the originating fault that results in this defect or what component will be fixed to eliminate this defect.
Defect counts can be reported as a function of time, creating a Defect Trend
diagram or report. They can also be reported in a Defect Density Report as a
function of one or more defect attributes, like severity or status. These types
of analysis provide a perspective on the trends or on the distribution of defects
that reveal the software's reliability.
For example, it's expected that defect discovery rates will eventually diminish
as the testing and fixing progresses. A defect or poor quality threshold can
be established at which point the software quality will be unacceptable. Defect
counts can also be reported based on the origin in the Implementation model,
allowing for detection of "weak modules", "hot spots", and
parts of the software that keep being fixed again and again, which indicates
more fundamental design flaws.
Only confirmed defects are included in an analysis of this kind. Not all reported defects denote an actual flaw; some might be enhancement requests outside of the project's scope, or may describe a defect that's already been reported. However, it's valuable to look at and analyze why many defects, which are either duplicates or not confirmed defects, are being reported.
Defect Reports
The Rational Unified Process recommends defect evaluation based on multiple reporting categories, as follows:
- Defect Distribution (Density) Reports allow defect counts to be shown as a function of one or two defect attributes.
- Defect Age Reports are a special type of defect distribution report. Defect age reports show how long a defect has been in a particular state, such as Open. In any age category, defects can also be sorted by another attribute, such as Owner.
- Defect Trend Reports show defect counts, by status (new, open, or closed), as a function of time. The trend reports can be cumulative or non-cumulative.
Many of these reports are valuable in assessing software quality. They are most useful when analyzed in conjunction with Test results and progress reports that show the results of the tests conducted over a number of iterations and test cycles for the application-under-test. The usual test criteria include a statement about the tolerable numbers of open defects in particular categories, such as severity class, which is easily checked with an evaluation of defect distribution. By sorting or grouping this distribution by test motivators, the evaluation can be focused on important areas of concern.
Normally tool support is required to effectively produce reports of this kind.
Defect Density Reports
Defect status versus priority
Give each defect a priority. It's usually practical and sufficient to have four levels of priority, such as:
- Urgent priority (resolve immediately)
- High priority
- Normal priority
- Low priority
Note: Criteria for a successful test could be expressed in terms of how the distribution of defects over these priority levels should look. For example, successful test criteria might be "no Priority 1 defects and fewer than five Priority 2 defects are open". A defect distribution diagram, such as the following, should be generated.
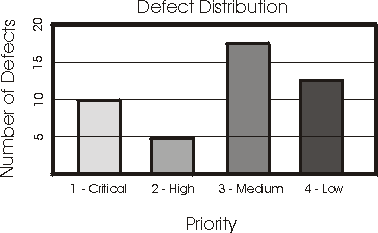
It's clear that the criteria has not been met. This diagram needs to include a filter to show only open defects, as required by the test criteria.
Defect status versus severity
Defect Severity Reports show how many defects there are for each severity class; for example, fatal error, major function not performed, minor annoyance.
Defect status versus location in the Implementation model
Defect Source Reports show distribution of defects on elements in the Implementation model.
Defect Aging Reports
Defect Age Analysis provides good feedback on the effectiveness of the testing and the defect removal activities. For example, if the majority of older, unresolved defects are in a pending-validation state, it probably means that not enough resources are applied to the retesting effort.
Defect Trend Reports
Defect Trend Reports identify defect rates and provide a particularly good view of the state of the testing. Defect trends follow a fairly predictable pattern in a testing cycle. Early in the cycle, the defect rates rise quickly, then they reach a peak, and decrease at a slower rate over time.
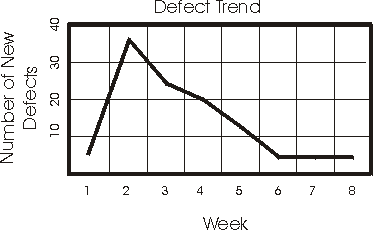
To find problems, the project schedule can be reviewed in light of this trend. For example, if the defect rates are still rising in the third week of a four-week test cycle, the project is clearly not on schedule.
This simple trend analysis assumes that defects are being fixed promptly and that the fixes are being tested in subsequent builds, so that the rate of closing defects should follow the same profile as the rate of finding defects. When this does not happen, it indicates a problem with the defect-resolution process; the defect fixing resources or the resources to retest and validate fixes could be inadequate.
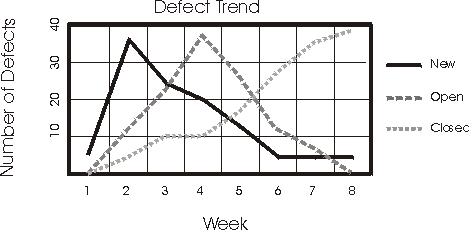
The trend reflected in this report shows that new defects are discovered and opened quickly at the beginning of the project, and that they decrease over time. The trend for open defects is similar to that for new defects, but lags slightly behind. The trend for closing defects increases over time as open defects are fixed and verified. These trends depict a successful effort.
If your trends deviate dramatically from these, they may indicate a problem and identify when additional resources need to be applied to specific areas of development or testing.
When combined with the measures of test coverage, the defect analysis provides a very good assessment on which to base the test completion criteria.
Performance Measures
Several measures are used for assessing the performance behaviors of the target-of-test and for focusing on capturing data related to behaviors such as response time, timing profiles, execution flow, operational reliability, and limits. Primarily, these measures are assessed in the Evaluate Test activity, however, there are performance measures that are used during the Execute Test activity to evaluate test progress and status.
The primary performance measures include:
- Dynamic Monitoring - real-time capture and display of the status and state of each test script being executed during the test execution.
- Response Time and Throughput Reports - measurement of the response times and throughput of the target-of-test for specified actors and use cases.
- Percentile Reports - percentile measurement and calculation of the data collected values.
- Comparison Reports - differences or trends between two (or more) sets of data representing different test executions.
- Trace Reports - details of the messages and conversations between the actor (test script) and the target-of-test.
Dynamic Monitoring
Dynamic monitoring provides real-time display and reporting during test execution, typically in the form of a histogram or a graph. The report monitors or assesses performance test execution by displaying the current state, status, and progress of the test scripts.
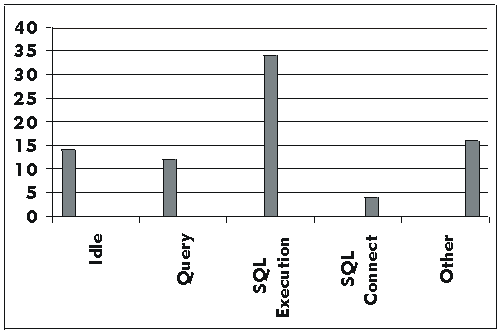
For example, in the preceding histogram, there are 80 test scripts executing the same use case. In this graph, 14 test scripts are in the Idle state, 12 in the Query, 34 in SQL Execution, 4 in SQL Connect, and 16 in the Other state. As the test progresses, you would expect to see the number of scripts in each state change. The displayed output would be typical of a test execution that is executing normally and is in the middle of its execution. However, if test scripts remain in one state or do not show changes during test execution, this could indicate a problem with the test execution, or the need to implement or evaluate other performance measures.
Response Time and Throughput
Reports
Response Time and Throughput Reports, as their name implies, measure and calculate the performance behaviors related to time and throughput (number of transactions processed). Typically, these reports are displayed as a graph with response time (or number of transactions) on the "y" axis and events on the "x" axis.
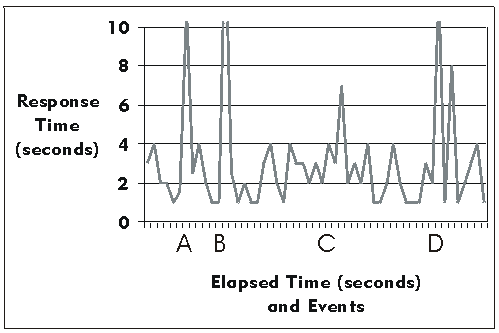
It's often valuable to calculate and display statistical information, such as the mean and standard deviation of the data values in addition to showing the actual performance behaviors.
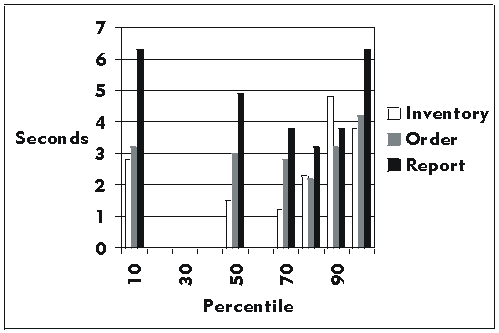
Percentile Reports
Percentile Reports provide another statistical calculation of performance by displaying population percentile values for data types collected.
Comparison Reports
It's important to compare the results of one performance test execution with that of another, so you can evaluate the impact of changes made between test executions on the performance behaviors. Use Comparison Reports to display the difference between two sets of data (each representing different test executions) or trends between many executions of test.
Trace and Profile Reports
When performance behaviors are acceptable or when performance monitoring indicates possible bottlenecks (such as when test scripts remain in a given state for exceedingly long periods), trace reporting could be the most valuable report. Trace and Profile Reports display lower-level information. This information includes the messages between the actor and the target-of-test, execution flow, data access, and the function and system calls.
