Guidelines: Data Model
Topics
- Overview
- Stages of Data Modeling
- Data Model Elements
- Evolution of the Data Model
- Round-Trip Engineering Considerations
Overview

Data Models are used to design the structure of the persistent data stores used by the system. The Unified Modeling Language (UML) profile for database design provides database designers with a set of modeling elements that can be used to develop the detailed design of tables in the database and model the physical storage layout of the database. The UML database profile also provides constructs for modeling referential integrity (constraints and triggers), as well as stored procedures used to manage access to the database.
Data Models might be constructed at the enterprise, departmental, or individual application level. Enterprise and departmental level Data Models can be used to provide standard definitions for key business entities (such as customer and employee) that will be used by all applications within a business or a business unit. These types of Data Models can also be used to define which system in the enterprise is the "owner" of the data for a specific business entity and what other systems are users of (subscribers to) the data.
This guideline describes the model elements of the UML profile for database modeling used to construct a Data Model for a relational database. Because there are numerous existing publications on general database theory, it does not cover this area. For background information on relational Data Models and Object Models see Concepts: Relational Databases and Object Orientation.
Note: The data modeling representations contained in this guideline are based on the UML 1.3. At the time that this guideline was developed, the UML 1.4 data-modeling profile was not available.
Stages of Data Modeling
As described in [NBG01], there are three general stages in the development of a Data Model: conceptual, logical, and physical. These stages of data modeling reflect the different levels of detail in the design of the persistent data storage and retrieval mechanisms of the application. A discussion of conceptual data modeling is provided in Concepts: Conceptual Data Modeling. Summaries of logical and physical data modeling are provided in the next two sections of this guideline.
Logical Data Modeling
In logical data modeling, the database designer is concerned with identifying the key entities and relationships that capture the critical information that the application needs to persist in the database. During the use-case analysis, use-case design, and class design activities, the database designer and the designer must work together to ensure that the evolving designs of the analysis and design classes for the application will adequately support the development of the database. During the class design activity, the database designer and the designer must identify the set of classes in the Design Model that will need to persist data in the database.
This set of persistent classes in the Design Model provides a Design Model View that, although different from the traditional Logical Data Model, meets many of the same needs. The persistent classes used in the Design Model function in the same manner as the traditional entities in the Logical Data Model. These design classes accurately reflect the data that must be persisted, including all of the data columns (attributes) that must be persisted and key relationships. This makes these design classes an excellent starting point for the physical database design.
Creating a separate Logical Data Model is an option. However, in the best case it would end up capturing the same information in a different form. In the worst case it would not, and thus in the end might not meet the business needs of the application. In particular, if the database is intended to service a single application, then the application's view of the data might be the best starting point. The database designer creates tables from this set of persistent design classes to form an initial Physical Data Model.
Still, situations might exist that would require the database designer to create an idealized design of the database that is independent from the application design. In this case, the logical database design is represented in a separate Logical Data Model that is part of the overall Artifact: Data Model. This Logical Data Model depicts the key logical entities and their relationships that are necessary to satisfy the system requirements for persisting data consistent with the overall architecture of the application. The Logical Data Model might be constructed using the modeling elements of the UML profile for database design described in later sections of this guideline. For projects that use this approach, close collaboration between the application designers and the database designers is absolutely critical to the successful development of the database design.
The Logical Data Model might be refined by applying the standard rules for normalization as defined in Concepts: Normalization prior to evolving the elements of the Logical Data Model to create the physical design of the database.
The figure below depicts the primary approach of using the Design Model classes as the source of logical database design information for creating an initial Physical Data Model. It also illustrates the alternative approach of using a separate Logical Data Model.
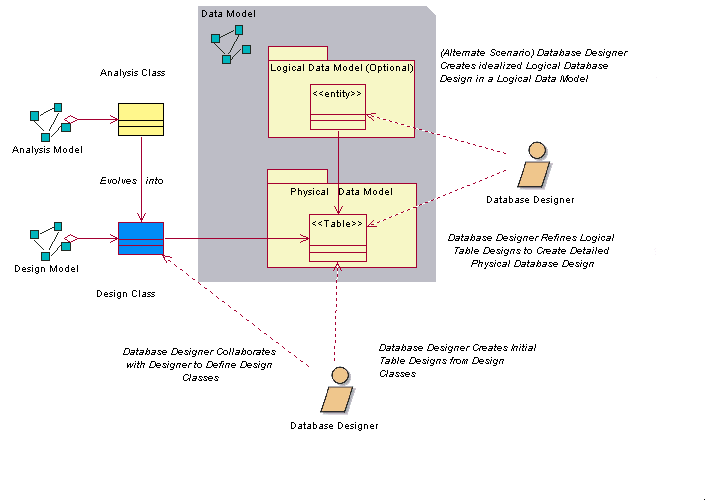
Logical Data Modeling Approaches
Physical Data Modeling
Physical data modeling is the final stage of development in the design of the database. The Physical Data Model consists of the detailed database table designs and their relationships created initially from the persistent design classes and their relationships. The mechanics of performing the transformation of the Design Model classes to tables is discussed in Guidelines: Forward-Engineering Relational Databases. The Physical Data Model is part of the Data Model; it is not a separate artifact.
The tables in the Physical Data Model have well-defined columns, as well as keys and indexes as needed. The tables might also have triggers defined as necessary to support the database functionality and referential integrity of the system. In addition to the tables, stored procedures have been created, documented, and associated with the database in which the stored procedure will reside.
The diagram below shows an example of some of the elements of the Physical Data Model. This example model is a part of the Physical Data Model of a fictional online auction application. It depicts four tables (Auction, Bid, Item, and AuctionCategory), along with one stored procedure (sp_Auction) and its container class (AuctionManagement). The figure also depicts the columns of each table, the primary key and foreign key constraints, and the indexes defined for the tables.
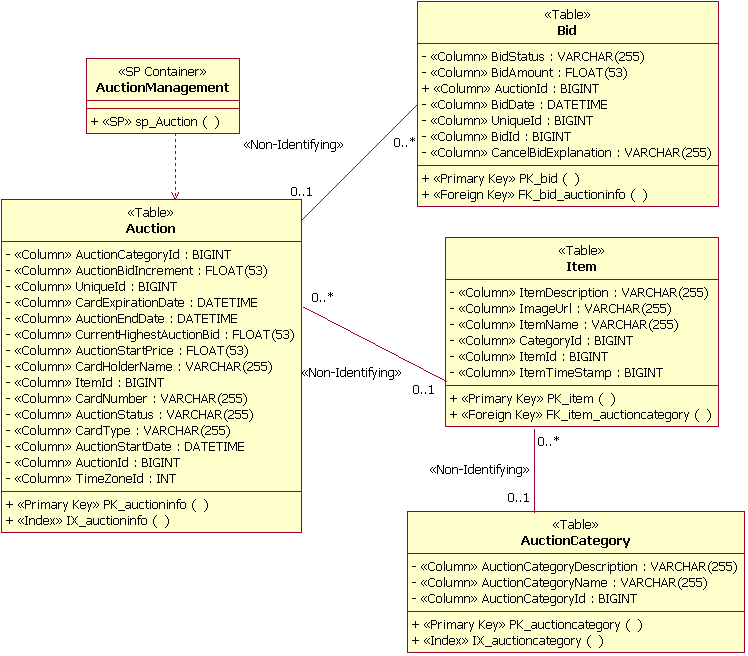
Example (Physical) Data Model Elements
The Physical Data Model also contains mappings of the tables to physical storage units (tablespaces) in the database. The figure below shows an example of this mapping. In this example, the tables Auction and OrderStatus are mapped to a tablespace called PRIMARY. The diagram also illustrates modeling the realization of the tables to the database (named PearlCircle in this example).
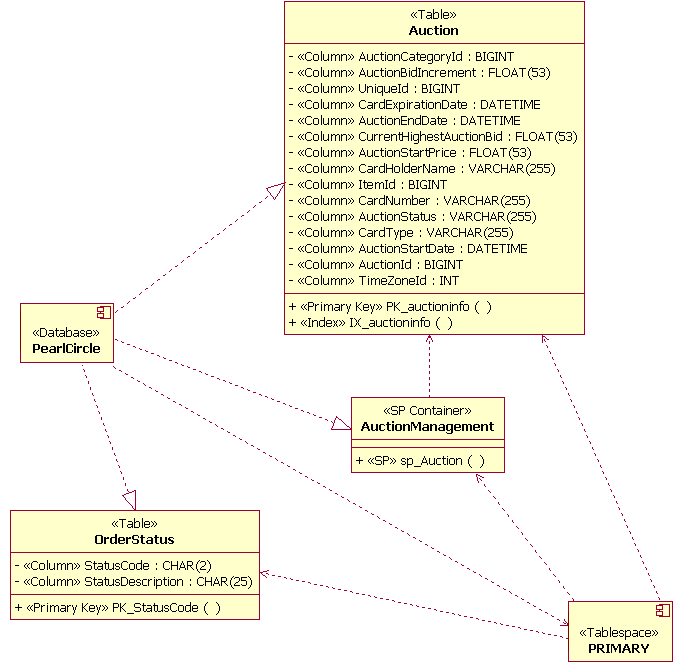
Example Data Storage Model Elements
On projects in which a database already exists, the database designer can reverse-engineer the existing database to populate the Physical Data Model. See Guidelines: Reverse-Engineering Relational Databases for more information.
Data
Model Elements
This section describes the general modeling guidelines for each major element of the Data Model based on the UML profile for database modeling. A brief description of each model element is followed by an example illustration of the UML model element. The Relationships section of this guideline includes a description of the usage of the model elements.
Package
Standard UML packages are used to group and organize elements of the Data Model. For example, packages might be defined to organize the Data Model into separate Logical and Physical Data Models. Packages might also be used to identify logically related groups of tables in the Data Model that constitute the major data "subject areas" of importance to the business domain of the application being developed. The figure below shows an example of two subject area packages (Auction Management and UserAccount Management) used to organize views and tables in the Data Model.
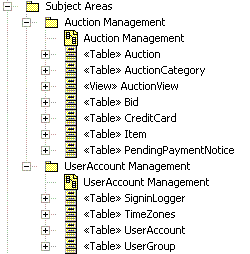
Subject Area Packages Example
Table
In the UML profile for database modeling, a table is modeled as a class with a stereotype of <<Table>>. The columns in the table are modeled as attributes with the stereotype of <<column>>. One or more columns might be designated as a primary key to provide for unique row entries in the table. Columns might also be designated as foreign keys. Primary keys and foreign keys have associated constraints that are modeled as the stereotyped operations of <<Primary Key>> and <<Foreign Key>> respectively. The figure below depicts the structure of an example table used to manage information about items sold at auction in a fictional online auction system.

Table Example
Tables might be related to other tables through the following types of relationships:
- identifying (composite aggregation)
- non-identifying (association)
The Relationships section of this guideline provides examples of how these relationships are used. Information on how these types of relationships can be mapped to Design Model elements appears in Guidelines: Reverse-Engineering Relational Databases.
Trigger
A trigger is a procedural function designed to run as a result of some action on the table in which the trigger resides. A trigger is defined to execute when a row in the table is inserted, updated, or deleted. Additionally, a trigger is designated to execute either before or after the table command executes. Triggers are defined as operations in a table. The operations are stereotyped <<Trigger>>.

Trigger Example
Index
Indexes are used as mechanisms for enabling faster access of information when specific columns are used to search the table. An index is modeled as an operation in the table with a stereotype of <<index>>. Indexes might be designated as unique and might be designated as clustered or unclustered. Clustered indexes are used to force the order of the data rows in the table to be aligned with the order of the index values. An example of an index operation (IX_auctioncategory) is shown in the figure below.

Index Example
View
A view is a virtual table with no independent persistent storage. A view has the characteristics and behaviors of a table and accesses the data in the columns from the table(s) with which the view has defined relationships. Views are used for providing more efficient access to information in one or more tables and also can be used to enforce business rules for restricting access to data in the tables. In the example below, an AuctionView has been defined as a "view" of information in the Auction table shown in the physical data modeling section of this guideline.
Views are modeled as classes with the stereotype of <<view>>. The attributes of the view class are the columns from the tables referenced by the view. The datatypes of the columns in the view are inherited from the tables with a defined dependency with the view.

View Example
Domain
A domain is a mechanism used to create user-defined datatypes that can be applied to columns across multiple tables. A domain is modeled as a class with the stereotype <<Domain>>. In the example below, a domain has been defined for a "zip + 4" zipcode.

Domain Example
Stored Procedure Container
A stored procedure container is a grouping of stored procedures within the Data Model. A stored procedure container is created as a UML class that is stereotyped <<SP Container>>. Multiple stored procedure containers can be created in a database design. Each stored procedure container must have at least one stored procedure.
Stored Procedure
A stored procedure is an independent procedure that typically resides on the database server. Stored procedures are documented as operations that are grouped into classes stereotyped as <<SP Container>>. The operations are stereotyped <<SP>>. The example below shows a single stored procedure operation (SP_Auction) in a container class named AuctionManagement. When designing stored procedures, the database designer must be cognizant of any naming conventions used by the specific RDBMS.

Stored Procedure Container and Stored Procedure Example
Tablespace
A tablespace represents the amount of storage space to be allocated to such items as tables, stored procedures and indexes. Tablespaces are linked to a specific database through a dependency relationship. The number of tablespaces and how the individual tables will be mapped to them depends on the complexity of the Data Model. Tables that will be accessed frequently might need to be partitioned into multiple tablespaces. Tables that do not contain large amounts of frequently accessed data might be grouped into a single tablespace.
A tablespace container is defined for each tablespace. The tablespace container is the physical storage device for the tablespace. Although multiple tablespace containers can exist for a single tablespace, it is recommended that a tablespace container be assigned to only a single tablespace. Tablespace containers are defined as attributes to the tablespace; they are not explicitly modeled.

Tablespace Example
Schema
A schema documents the organization or structure of the database. A schema is represented as a package that is stereotyped <<Schema>>. When a schema is defined as a package, the tables that make up that package should be contained within the schema. A dependency between the database and the schema is created to document the relationship between the database and the schema.

Schema Example
Database
A database is a collection of data that is organized such that the information in it can be accessed and managed. The management and access of information in the database is performed through the use of a commercial database management system (DBMS). A database is represented in the Data Model as a component that is stereotyped <<Database>>.

Database Example
Relationships
The UML profile for database modeling defines the valid relationships between the major elements of the Data Model. The following sections provide examples of the different relationship types.
Non-Identifying
A non-identifying relationship is a relationship between two tables that independently exist within the database. A non-identifying relationship is documented by using an association between the tables. The association is stereotyped <<Non-Identifying>>. The example below depicts a non-identifying relationship between the Item table and the AuctionCategory table.
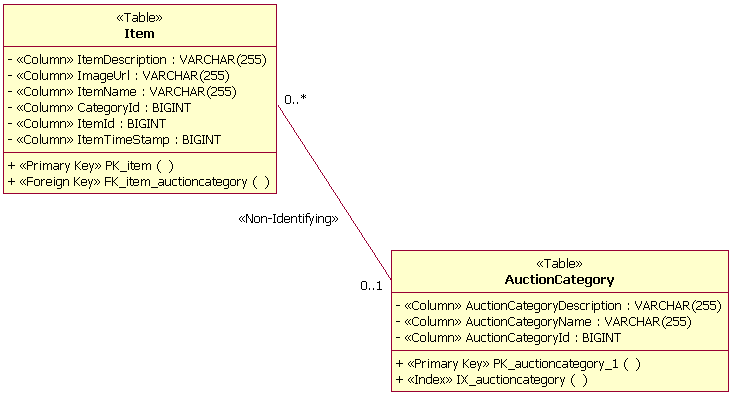
Non-Identifying Relationship Example
Identifying
An identifying relationship is a relationship between two tables in which the child table must coexist with the parent table. An identifying relationship is documented by using a composite aggregation between two tables. The composite aggregation is stereotyped as <<Identifying>>. The figure below is an example of an identifying relationship. This example shows that instances of the child table (CreditCard) must have an associated entry in the parent table (UserAccount).
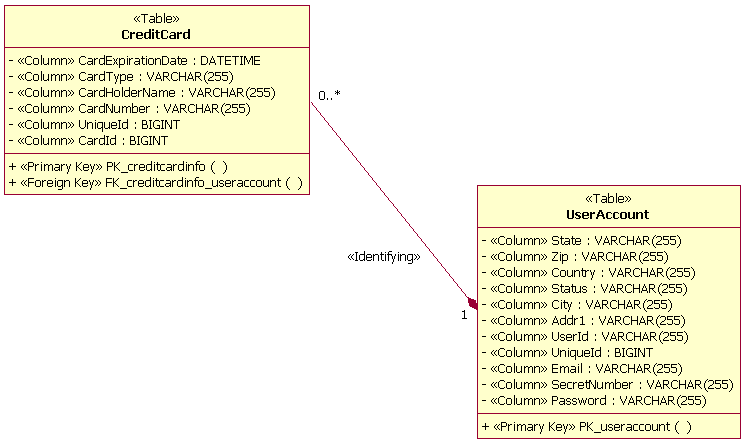
Identifying Relationship Example
For both the association and composite aggregation, multiplicity should be defined to document the number of rows in the relationship. In the example above, for each row in the UserAccount table, there can be 0 or more CreditCard rows in the CreditCard table. For each row in the CreditCard table, there is exactly one row in the UserAccount table. Multiplicity is also known as cardinality.
Database Views
When defining a database view's relationship with a table, a dependency relationship is used, drawn from the view to the table. The stereotype of the dependency is <<Derive>>. Typically, the view dependency is named, and the name of the dependency is the same as the name of the table that is defined in the dependency relationship with the database view.
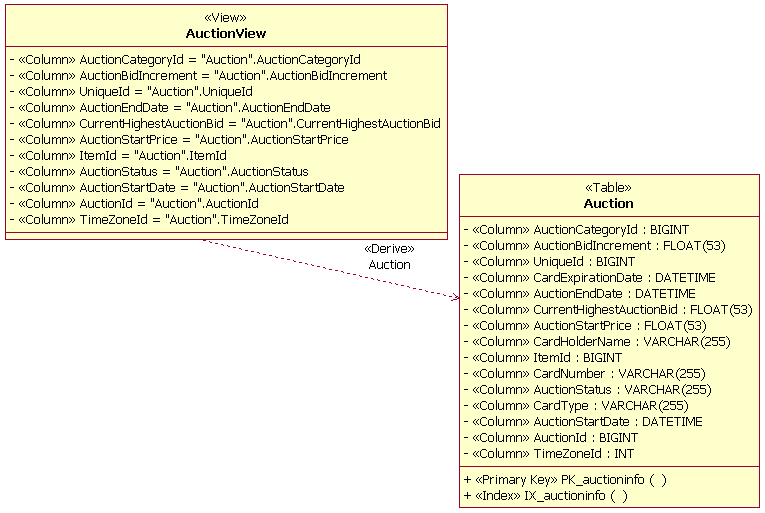
View and Table Dependency Relationship Example
Tablespace
A dependency relationship is used to link a tablespace to a specific database. As shown in the figure below, the relationship is drawn to show that the database has the dependency on the tablespace. Multiple tablespaces can be related to a single database in the model.
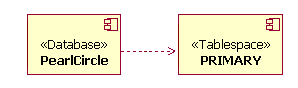
Tablespace and Database Dependency Relationship Example
A dependency relationship is used to document the relationships between tablespaces and the tables within a tablespace. One or many tables can be related to a single tablespace, and a single table can be related to multiple tablespaces. The example below shows that the table Auction is assigned to a single tablespace named PRIMARY.
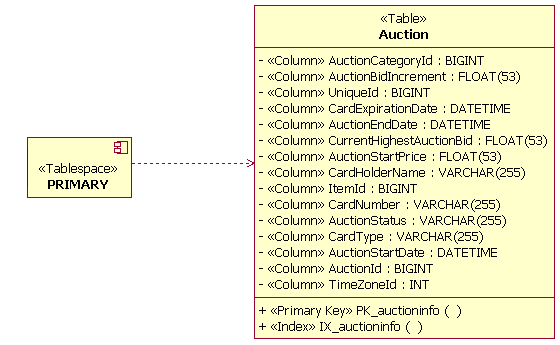
Table and Tablespace Dependency Relationship Example
Realizations
Realizations are used to establish the relationship between a database and the tables that exist within it. A table can be realized by multiple databases in the Data Model.
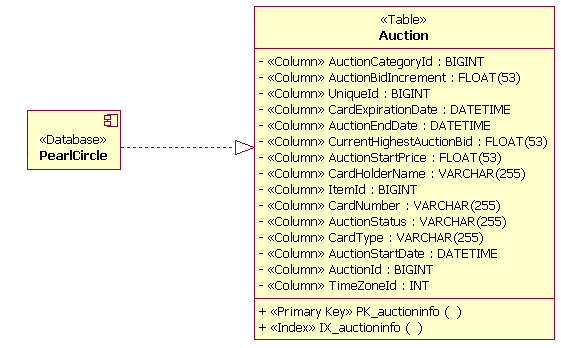
Table and Database Realization Relationship Example
Stored Procedures
A dependency relationship is used to document the relationship between the stored procedure container and the tables that the stored procedures within the stored procedure containers act upon. The example below depicts this type of relationship by showing that the stored procedure SP_Auction will be used to access information in the Auction table.
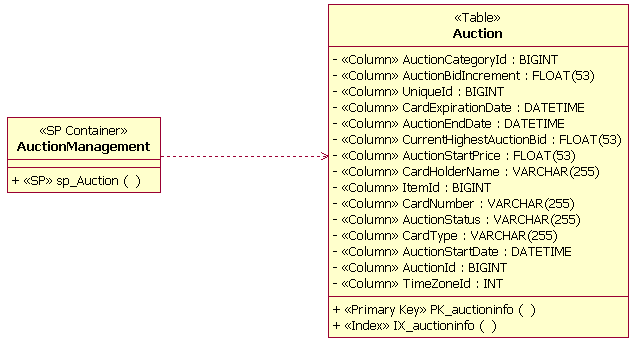
Stored Procedure Container and Table Dependency Relationship Example
Evolution of the Data Model
Inception Phase
In the inception phase, initial data modeling activities might be performed in conjunction with the development of any proof-of-concept prototypes as part of the"Perform architectural synthesis workflow detail" activities. On projects in which a database already exists, the database designer might reverse-engineer the existing database to develop an initial Physical Data Model based on the structure of the existing database. See Guidelines: Reverse-Engineering Relational Databases for more information. Elements of the Physical Data Model might be transformed into Design Model elements as needed to support any proof-of-concept prototyping activities.
Elaboration Phase
The goal of the elaboration phase is to eliminate technical risk and to produce a stable (baselined) architecture for the system. In large-scale systems, poor performance resulting from a badly designed Data Model is a major architectural concern. As a result, both data modeling and the development of an architectural prototype that allows the performance of the database to be evaluated are essential to achieving a stable architecture. As the architecturally significant use cases are detailed and analyzed in each iteration, Data Model elements are defined based on the development of the persistent class designs from the use cases. As the class designs stabilize, the database designer might periodically transform the class designs into tables in the Data Model and define the appropriate data storage model elements.
By the end of the elaboration phase, the major database structures (tables, indexes, and primary and foreign key columns) must be put in place to support the execution of the defined architecturally significant scenarios for the application. In addition, representative data volumes must be loaded into the database to support architectural performance testing. Based on the results of performance testing, the Data Model might need to be adjusted with optimization techniques, including but not limited to de-normalizing, optimizing physical storage attributes or distribution, and indexing.
Construction Phase
Major restructuring of the Data Model must not occur during the construction phase. Additional tables and data storage elements might be defined during the construction phase iterations based on the detailed design of the set of use cases and approved change requests allocated to the iteration. A primary focus of database design during the construction phase is to continually monitor the performance of the database and optimize the database design as needed through de-normalizing, defining indexes, creating database views, and other optimization techniques.
The Physical Data Model is the design artifact that the database designer maintains during the construction phase. It can be maintained by either making direct updates in the model or as a result of a tool reading updates that have been made directly on the database.
Transition Phase
The Data Model, like the Design Model, is maintained during the transition phase in response to approved change requests. The database designer must keep the Data Model synchronized with the database as the application goes through final acceptance test and is deployed into production.
Round-trip Engineering Considerations
If a development team is using modern visual modeling tools that have the ability to convert classes to tables (and vice versa) and/or has the ability to reverse and forward engineer databases, then the team needs to establish guidelines for managing the transformation and engineering processes. The guidelines are primarily needed for large projects in which a team is working in parallel on the database and application design. The development team must define the points in the development of the application (build/release cycle) at which it will be appropriate to perform the class-to-table transformations and to forward-engineer the database. Once the initial database is created, the development team must define guidelines for the team to manage the synchronization of the Data Model and database as the design and code of the system evolve throughout the project.
|
This content developed or partially developed by  Applied Information Sciences. Applied Information Sciences.
|
